
As detailed on the About page, everything Pathfinder Labs does is centered around the concept of closing feedback loops. The purpose of Pathfinder's technology is to identify patterns and latencies in feedback, helping providers and participants visualize and understand program impact, and optimize their growth. When an organization provides a service - holds an event, offers a treatment series, conducts training, or whatever the speciality - the best way to track program efficacy is to ask for participant feedback. That's nothing new; many products, services, restaurants, even government policy writers ask for feedback to make sure they are meeting the needs of their customers. Honest, thorough feedback offers benefits throughout the community:
A closed feedback loop is a great start to guiding improvements in individuals, programs, and communities. What technology can do is reduce or eliminate problematic factors; the same opinions and emotions that make feedback valuable as an outlet and community builder also make it much more challenging to use as a tool for making efficient, objective decisions. A trained, calibrated technology platform can help mitigate:
We are interested in impact: what effect does a program have on the different elements making up their participants' well-being? What motivates them to seek services, or return to events and appointments? Is the program having a lasting effect on their anxiety and resilience, or creating diligent habits? This is all about personality. Personality prompts us to behave in a way that generates emotions that affect our behaviors to change our emotions. These are all linked, but the one that is hardest to change, and at the base of it all, is personality. If a provider or series of providers can impact emotions and behaviors enough, they may be able to influence a shift in personality. Reduce stress often enough, eventually you may find you are less predisposed to being anxious. Your baseline is lower: the anxiety facet of emotional range (or neuroticism) is reduced. We reasoned we couldn't very well ask someone to do a full personality test every time they provided feedback, and we wouldn't be likely to get accurate or standardized responses anyway (see the first section). Computers and math and statistics and data engineering to the rescue! Yeah, we're nerds. It's cool.
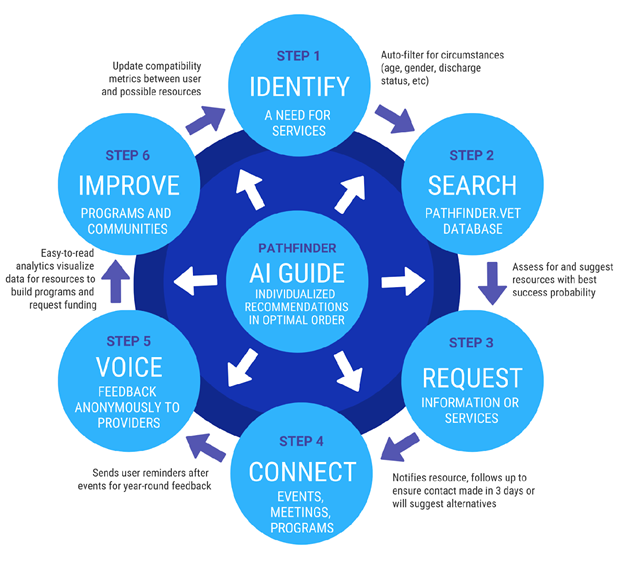
There are three primary components that make up the Pathfinder Labs technology:
Hold onto your hats, because here's where it gets fun.
Graphs! And some other pretty pictures, but all help visualize the data. Once a month, we share a little piece of what we learned in our User and Provider newsletters, but there are also dashboards, reports, and other results.
To the moon! Sort of. The plan is to ultimately understand the different paths (see what we did there) we can take at different career stages that lead to a high probability of "success." So first we use unsupervised machine learning to train the machine in figuring out what success looks like. Then we can look at how users with different personalities, military career stages, and use of various providers found success. This lets us use supervised learning to find the patterns that led to their success. For our providers, we are looking at how they find participants. We would like to help them target those who are most in need of their service, especially those who have room to grow in a particular attribute in which the provider specializes. We also want to match motivations, and steer people to providers that are a good personal fit. IMPORTANT NOTE: We will never share an individual result with a provider or employer, only aggregated analysis, to avoid having personality probabilities be a part of active selections for services (too much potential to be discriminatory). We only will advise on what a provider might look for during the recruiting process or what types of questions they might consider asking applicants. We are also using this technology to help programs and services offer more to their community by examining overall area needs, and comparing those needs to the services available.